【容错计算】
拼译:fault-tolerant computing
计算机工作的可信赖性是衡量计算机的一项重要指标。早在1956年冯·诺伊曼(von Neumann)就曾指出:能用大量不可靠元件来组成可靠的计算机。由于航天工业的需要诞生了“容错计算”,目前容错计算已深入到许多领域并出现了一些容错计算机系列产品。在海湾战争中容错机也发挥了巨大的作用。容错概念已逐渐深入到电子和机械其它行业。
“容错”是指能容忍故障的一种特殊机制。故障可大致分为由物理缺陷或损坏所引起的永久故障,由疲劳与变形或工作于边缘状态所产生的间歇故障(0值与1值间的振荡),以及由电磁、辐射等外部干扰所引起的瞬时故障。瞬时故障出现的机会较多,它们瞬间即逝,因此不能采用诊断方法来确定它,只有采用容错设计来屏蔽它的影响。衡量系统可信赖性通常采用两个指标:即可用性与可靠性。假设系统运行到失效的平均时间为MTTF,修复故障的平均时间为MTTR,则系统的可用性A=MTTF/(MTTF+MTTR)。具有高可靠性系统其MTTF远大于MTTR,因而A接近1。若MTTF较小则A就随MTTR的大小而改变。系统的可靠性R=Pr(无故障)+Pr(正错运行/故障)×Pr(故障)。使第1项增加的方法叫避错法,即用加强元件筛选和严格加工工艺来增加无故障的概率。但是在达到一定水平之后要想再提高,将引起成本的急剧上升,因此只好提高在故障情况下系统仍能正常运行的概率,这就是容错的方法。容错的实质是用多余的资源(例如硬件、软件、时间、信息位以及逻辑状态等)来提高可靠性。硬件冗余是用N个模块执行同一任务并将计算结果经表决器输出,这样即使有t个模块故障(t<[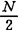 ]),也能获得正确的计算结果。当然也可以让一些模块作为备份,当表决器指示出故障模块时即以备份模块来顶替。软件冗余是用软件方法来执行表决并查出故障模块,但由于软件的时间开销不适合用于要求实时性强的场合。时间冗余是把N个模块的并行执行换成单个模块重复执行N次并将各次结果进行表决,它显然不能处理模块的永久故障,处理速度也要降低,但在数据通讯中仍经常采用这一技术。信息冗余是在必要的信息位外附加了一些用于检错或纠错的特殊位。纠错码技术已经大量地运用于信息的存储、传送和运算的纠错。逻辑状态冗余是将多值逻辑中的某些状态用于检错、纠错或容错,目前这种技术尚不成熟。精心设计有时也会相对提高容错能力,虽然没有消耗资源,却花费了人的精力。容错计算涉及以下技术:(1)用模块冗余进行检错与屏蔽错误。二模、三模或多模系统分别采用各种比较或表决方法以获得正确的输出结果。(2)误差检测码和纠错码。总线、存储器和寄存器中常见的是奇偶校验码,汉明码用于存储器的检错与纠错,循环码用于通讯通道和磁盘存贮器,n中取m码用于只读存储器,算数码用于算术逻辑部件的检错。(3)自校验逻辑。常见的有两个二进位的双轨逻辑,其中两个状态是合法的,另两个状态是非法的。于是有故障保险、自测试以及全自校验等级别。(4)协议检查与时间检查。将预计状态与现行状态比较以检查有无故障。如果核查的是时间,则可用“定时看门狗”以检查是否超过时限。对于被瞬时故障打乱了的程序,想恢复又想节省付本的信息,可以重作该指令或该总线周期,多次重作不能恢复的就认定为永久的故障。(5)故障的隔离。将故障的影响限制在一定范围内,使其不干扰正常部份。(6)修复与重构。将故障模块断电并切除,用备份模块换入即可修复,系统功能不减。如果换入的是冷备份(未带电或执行其它任务者)就需要进行初始化。执行同一任务的备份不须初始化,但要多消耗资源。在多机系统中可以将切除后剩下的好模块重新构成一新系统,新系统的性能比原系统有所降低。这种逐渐降低性能但不致中断任务的方法叫做缓慢降级。(7)系统恢复。在重构之后或故障修复之后要使系统恢复工作,必须预置检查点,把系统卷回到上一检查点而不是任务的最初点,以保留大部分已计算过的结果。20世纪60年代期间美国贝尔(Bell)实验室设计了电子开关系统ESS,其目标是使40年中MTTR仅为两小时;古柏(Cooper)等研制的1台三模冗余计算机帮助人类登上了月球。美国喷气推进实验室(JPL)研制的1台样机(1961~1970)称为自检自修计算机STAR,用于宇宙飞船的制导与航天资料的收集,它的特点是无人维修而服务时间长达10年。70年代初期在美国电气和电子工程师协会(IEEE)下成立了容错计算技术委员会,从1971年起每年举行1次国际容错计算会议,大大推进了这一领域研究的开展。由美国斯坦福研究所(SRI)1972年设计的用软件实现的容错机SIFT用于飞行控制。设计的目标是使在10h飞行期间系统的失效率为10-9/h,相当于能连续工作10000年。它采用了能相互作点到点通讯的8个模块,每个模块的失效率为10-6/h。即是说采用容错设计使可靠性提高了3个数量级。1976年美国推出了Tandem容错机系列的“不停顿1型”是第一个高可用的商品化产品。它能不停顿地运行,即检测故障、将故障模块切除、修好的模块重组进系统等工作均不影响其正常任务的执行;任何硬件失效均不影响数据的完整性;电源、存储器和外围模块可以并入而不冲击应用软件。Tandem机在市场上为容错机建立了声誉。80年代初西沃赖克(Siewiorek)等出版的《可靠系统设计的理论与实践》,总结了当时的容错技术,内容丰富而全面。1980年美国STRATUS公司推出了STRATUS容错计算机。它用双总线连结双份的处理机、外存、通讯器、联结器等模块。两个同样模块之间连续进行比较核对以便及时发现故障。双份中的每一半模块各用一个电源供电。每一半的处理器模块又是两个相互比较的双处理器,当比较结果不相同时就亮起红灯并启动“维护中断”,另一半的两个模块立即取代出故障的一半以控制输出,工作不会中断。操作系统执行中断程序,判明若为瞬时故障则再投入运行;若为永久故障就自动通过电话线通知总公司的用户服务中心。中心核实了问题后,就用急件把替换板和恢复程序连夜寄给用户。用户在收到替换板后才知道机器中已潜伏下故障,在不中断任务执行的情况下带电拔插更换新板。新板向系统申请中断,由正在运行的处理机将其同步,使其逐渐并入系统。用这种工作方式保证了工作不致停顿。STRATUS计算机在美国加州经受了地震的考验,是在恢复供电之后唯一能重新继续工作的计算机。它在中国举办的亚运会中也立了功。从30多年来的发展可以看出容错计算的发展趋势是:(1)初期。以软件容错为主,以SIFT机为代表。可以将几台现成机器用软件组成容错系统,组装较容易,修改较方便。然而缺点是软件的时间开销大,不适用于实时性强的场合;须把应用程序分段以便比较,不易被用户接受。(2)中期。以硬件容错为主,以STRATUS机为代表。它克服了软件容错的缺点,但性能价格比不高,因为不管任务是否关键,一律都要用四模来处理。(3)现期。以分布式容错与多机容错为主,例如一个大型分布式系统的操作系统可根据每个任务对可靠性的不同要求来分配处理机数。例如一般任务用单机处理,关键任务用三机或五机仿作,这样可提高性能价格比。如何对大型脉动阵列和细胞并行系统进行诊断与容错设计是当前的热门研究课题。(4)将来。以硅片容错为主。随着整片集成电路的发展,以前的多机系统可以集成在一块硅片上。只有采用容错的设计才能经测试后剔除不合格的模块,把剩下的好模块组成系统以提高电路的合格率;同样在运行时随时剔除出现故障的模块以提高系统的可用性。这一技术目前还处于探索阶段。【参考文献】:1 Siewiorek D P,et al.The Theory and Practice of Reliable System Design,19822 Nelson V P.Computer,1990,(7);23(7):19~253 Siewiorek D P.Computer 1990,(7);23(7):26~374 Geist R,et al.Computer,1990,(7):23(7):52~615 Fujiwara E.Computer,1990,(7):23(7):63~726 Koron E,et al.Compater,1990,(7):23(7):73~83
]),也能获得正确的计算结果。当然也可以让一些模块作为备份,当表决器指示出故障模块时即以备份模块来顶替。软件冗余是用软件方法来执行表决并查出故障模块,但由于软件的时间开销不适合用于要求实时性强的场合。时间冗余是把N个模块的并行执行换成单个模块重复执行N次并将各次结果进行表决,它显然不能处理模块的永久故障,处理速度也要降低,但在数据通讯中仍经常采用这一技术。信息冗余是在必要的信息位外附加了一些用于检错或纠错的特殊位。纠错码技术已经大量地运用于信息的存储、传送和运算的纠错。逻辑状态冗余是将多值逻辑中的某些状态用于检错、纠错或容错,目前这种技术尚不成熟。精心设计有时也会相对提高容错能力,虽然没有消耗资源,却花费了人的精力。容错计算涉及以下技术:(1)用模块冗余进行检错与屏蔽错误。二模、三模或多模系统分别采用各种比较或表决方法以获得正确的输出结果。(2)误差检测码和纠错码。总线、存储器和寄存器中常见的是奇偶校验码,汉明码用于存储器的检错与纠错,循环码用于通讯通道和磁盘存贮器,n中取m码用于只读存储器,算数码用于算术逻辑部件的检错。(3)自校验逻辑。常见的有两个二进位的双轨逻辑,其中两个状态是合法的,另两个状态是非法的。于是有故障保险、自测试以及全自校验等级别。(4)协议检查与时间检查。将预计状态与现行状态比较以检查有无故障。如果核查的是时间,则可用“定时看门狗”以检查是否超过时限。对于被瞬时故障打乱了的程序,想恢复又想节省付本的信息,可以重作该指令或该总线周期,多次重作不能恢复的就认定为永久的故障。(5)故障的隔离。将故障的影响限制在一定范围内,使其不干扰正常部份。(6)修复与重构。将故障模块断电并切除,用备份模块换入即可修复,系统功能不减。如果换入的是冷备份(未带电或执行其它任务者)就需要进行初始化。执行同一任务的备份不须初始化,但要多消耗资源。在多机系统中可以将切除后剩下的好模块重新构成一新系统,新系统的性能比原系统有所降低。这种逐渐降低性能但不致中断任务的方法叫做缓慢降级。(7)系统恢复。在重构之后或故障修复之后要使系统恢复工作,必须预置检查点,把系统卷回到上一检查点而不是任务的最初点,以保留大部分已计算过的结果。20世纪60年代期间美国贝尔(Bell)实验室设计了电子开关系统ESS,其目标是使40年中MTTR仅为两小时;古柏(Cooper)等研制的1台三模冗余计算机帮助人类登上了月球。美国喷气推进实验室(JPL)研制的1台样机(1961~1970)称为自检自修计算机STAR,用于宇宙飞船的制导与航天资料的收集,它的特点是无人维修而服务时间长达10年。70年代初期在美国电气和电子工程师协会(IEEE)下成立了容错计算技术委员会,从1971年起每年举行1次国际容错计算会议,大大推进了这一领域研究的开展。由美国斯坦福研究所(SRI)1972年设计的用软件实现的容错机SIFT用于飞行控制。设计的目标是使在10h飞行期间系统的失效率为10-9/h,相当于能连续工作10000年。它采用了能相互作点到点通讯的8个模块,每个模块的失效率为10-6/h。即是说采用容错设计使可靠性提高了3个数量级。1976年美国推出了Tandem容错机系列的“不停顿1型”是第一个高可用的商品化产品。它能不停顿地运行,即检测故障、将故障模块切除、修好的模块重组进系统等工作均不影响其正常任务的执行;任何硬件失效均不影响数据的完整性;电源、存储器和外围模块可以并入而不冲击应用软件。Tandem机在市场上为容错机建立了声誉。80年代初西沃赖克(Siewiorek)等出版的《可靠系统设计的理论与实践》,总结了当时的容错技术,内容丰富而全面。1980年美国STRATUS公司推出了STRATUS容错计算机。它用双总线连结双份的处理机、外存、通讯器、联结器等模块。两个同样模块之间连续进行比较核对以便及时发现故障。双份中的每一半模块各用一个电源供电。每一半的处理器模块又是两个相互比较的双处理器,当比较结果不相同时就亮起红灯并启动“维护中断”,另一半的两个模块立即取代出故障的一半以控制输出,工作不会中断。操作系统执行中断程序,判明若为瞬时故障则再投入运行;若为永久故障就自动通过电话线通知总公司的用户服务中心。中心核实了问题后,就用急件把替换板和恢复程序连夜寄给用户。用户在收到替换板后才知道机器中已潜伏下故障,在不中断任务执行的情况下带电拔插更换新板。新板向系统申请中断,由正在运行的处理机将其同步,使其逐渐并入系统。用这种工作方式保证了工作不致停顿。STRATUS计算机在美国加州经受了地震的考验,是在恢复供电之后唯一能重新继续工作的计算机。它在中国举办的亚运会中也立了功。从30多年来的发展可以看出容错计算的发展趋势是:(1)初期。以软件容错为主,以SIFT机为代表。可以将几台现成机器用软件组成容错系统,组装较容易,修改较方便。然而缺点是软件的时间开销大,不适用于实时性强的场合;须把应用程序分段以便比较,不易被用户接受。(2)中期。以硬件容错为主,以STRATUS机为代表。它克服了软件容错的缺点,但性能价格比不高,因为不管任务是否关键,一律都要用四模来处理。(3)现期。以分布式容错与多机容错为主,例如一个大型分布式系统的操作系统可根据每个任务对可靠性的不同要求来分配处理机数。例如一般任务用单机处理,关键任务用三机或五机仿作,这样可提高性能价格比。如何对大型脉动阵列和细胞并行系统进行诊断与容错设计是当前的热门研究课题。(4)将来。以硅片容错为主。随着整片集成电路的发展,以前的多机系统可以集成在一块硅片上。只有采用容错的设计才能经测试后剔除不合格的模块,把剩下的好模块组成系统以提高电路的合格率;同样在运行时随时剔除出现故障的模块以提高系统的可用性。这一技术目前还处于探索阶段。【参考文献】:1 Siewiorek D P,et al.The Theory and Practice of Reliable System Design,19822 Nelson V P.Computer,1990,(7);23(7):19~253 Siewiorek D P.Computer 1990,(7);23(7):26~374 Geist R,et al.Computer,1990,(7):23(7):52~615 Fujiwara E.Computer,1990,(7):23(7):63~726 Koron E,et al.Compater,1990,(7):23(7):73~83(重庆大学博士生导师陈廷槐教授撰)