【逐步Fisher判别方法】
拼译:stepwise Fisher,s discritninating method
判别分析是多元分析中应用性较强的一个分支。它根据研究对象y被分为k个总体(类别)时,可能与m个因子x1,x2,…,xm有关,从每个总体Gα中抽取nα个样品数据 ,
,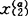 ,…,
,…,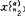 (α=1,2,…,k;n1+…+nk=n). (1)
(α=1,2,…,k;n1+…+nk=n). (1)
依一定的判别准则建立判别模型。比如,当使用Fisher判别准则建立线性判别函数
y=β1x1+…+βmxm (2)
后,就可以由式(2)对任一样品x(i)=(xi1,xi2,…,xim)′的属类作出预测。例如,根据n1个正常人及n2个冠心病人都同样检查了m个因子的数据,依判别准则得出模型(2)后,就可以对某个也做了同样m个因子(症状)数据的人作出是否得了冠心病的诊断。又如可以利用历年的气象因子的数据资料建立的判别模型来预测明年某地的雨量是偏多、偏少、或正常,等等。
怎样由已知的n个样品数据(1),按一定的判别准则求出βj(j=1,2,…,m)的估计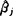 而建立判别效果好的判别式?这是判别分析的核心问题。目前常用的方法有Bayes准则、Fisher准则、距离判别和非参数方法等。无论采用哪种准则或方法建立的判别模型对任一样品作出预测推断时,都有可能会产生错判。根据所用方法建立的判别准则,都相应地有一套计算错判概率的理论方法。为了使得建立的判别模型有实用价值,不管使用怎样的数学错判原则,都必须保证原样品的回代正确率η愈大愈好。从实用的要求而言,若η<80%,则模型的外延预测能力是比较差的;若η>90%,则外延预测的错判将可能大大地减少。实际工作者往往知道y与某些因子有关。因此,选择判别能力强的因子变量xj(j=1,2,…,m)建立判别模型是判别分析中最重要的问题。如果Gα(α=1,2,…,k)遵从正态分布,利用Bayes准则所建立的逐步判别分析方法是60年代中期以来国内外使用最为普遍的计算程序。该方法筛选因子变量的依据是Wilks统计量,按此原则建立的判别模型有时达不到使样本回代正确率最高这一要求。1990年谭良也用判别符合率的观点讨论了Bayes准则下的判别分析方法的因子筛选问题。当Gα的分布任意时,至今尚无提供较好的选择因子的方法。比如关于距离判别方法的筛选因子问题,张尧庭、方开泰曾提出利用已选的r个因子的总体分辨率(其中
而建立判别效果好的判别式?这是判别分析的核心问题。目前常用的方法有Bayes准则、Fisher准则、距离判别和非参数方法等。无论采用哪种准则或方法建立的判别模型对任一样品作出预测推断时,都有可能会产生错判。根据所用方法建立的判别准则,都相应地有一套计算错判概率的理论方法。为了使得建立的判别模型有实用价值,不管使用怎样的数学错判原则,都必须保证原样品的回代正确率η愈大愈好。从实用的要求而言,若η<80%,则模型的外延预测能力是比较差的;若η>90%,则外延预测的错判将可能大大地减少。实际工作者往往知道y与某些因子有关。因此,选择判别能力强的因子变量xj(j=1,2,…,m)建立判别模型是判别分析中最重要的问题。如果Gα(α=1,2,…,k)遵从正态分布,利用Bayes准则所建立的逐步判别分析方法是60年代中期以来国内外使用最为普遍的计算程序。该方法筛选因子变量的依据是Wilks统计量,按此原则建立的判别模型有时达不到使样本回代正确率最高这一要求。1990年谭良也用判别符合率的观点讨论了Bayes准则下的判别分析方法的因子筛选问题。当Gα的分布任意时,至今尚无提供较好的选择因子的方法。比如关于距离判别方法的筛选因子问题,张尧庭、方开泰曾提出利用已选的r个因子的总体分辨率(其中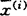 为第i个总体样本均值向量;V(i)为样本协方差阵)
为第i个总体样本均值向量;V(i)为样本协方差阵)
和预先选定的H0,采用统计量

筛选因子。当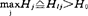 时,则选入因子xlj,而剔除因子的准则也类似式(4)的统计量。但这里存在H0的选择标准及式(4)的确定问题。因为直到现在Hj的分布是未知的,所以实际应用中尚缺乏理论根据。对于Fisher判别方法,至今尚未提出怎样筛选因子。
时,则选入因子xlj,而剔除因子的准则也类似式(4)的统计量。但这里存在H0的选择标准及式(4)的确定问题。因为直到现在Hj的分布是未知的,所以实际应用中尚缺乏理论根据。对于Fisher判别方法,至今尚未提出怎样筛选因子。
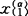 ,
,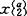 ,…,
,…,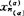 取自均值向量为μ(α),协方差阵为V(α)的总体Gα(α=1,2,…,k);n1+…+nk=n。根据方差分析的原理,对组内离差阵
取自均值向量为μ(α),协方差阵为V(α)的总体Gα(α=1,2,…,k);n1+…+nk=n。根据方差分析的原理,对组内离差阵
进行分解
E=LL′ (6)
并由组间离差阵

与L所形成的特征方程
|L-1BL/-1-λI|=0 (8)
之后,按下述逐步筛选因子的具体步骤建立Fesher判别式(其中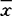 表示样本的均值向量,
表示样本的均值向量,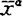 表示总体Gα的样本均值向量,α=1,2,…,k)。
表示总体Gα的样本均值向量,α=1,2,…,k)。
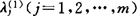 .①求出对应于
.①求出对应于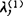 的特征向量
的特征向量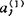 ,则对任意的样品x所建立的判别式为:
,则对任意的样品x所建立的判别式为: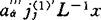 (9)②利用式(9)回代计算各样品的对应值
(9)②利用式(9)回代计算各样品的对应值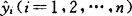 。从而在求出各类的平均值
。从而在求出各类的平均值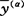 后,就可确定出判别任一样品x的鉴别临界值
后,就可确定出判别任一样品x的鉴别临界值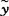 。(α=1,2,…,k;c=1,2,…,k-1)。最后可以依各样品的数据yj判别它的属类与原分类相符合的正确数
。(α=1,2,…,k;c=1,2,…,k-1)。最后可以依各样品的数据yj判别它的属类与原分类相符合的正确数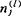 。③令
。③令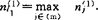 (10)则第一个吸收的因子为xl1,记为(&)={l1}。其中(&)既表示入选因子的下标集,也表示吸收因子的个数,如果有
(10)则第一个吸收的因子为xl1,记为(&)={l1}。其中(&)既表示入选因子的下标集,也表示吸收因子的个数,如果有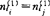 ,且li≠lj及
,且li≠lj及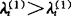 ,则吸收因子xl1=xli.2.固定因子xl1,结合其余m-1个因子的每一个,依式(8)计算
,则吸收因子xl1=xli.2.固定因子xl1,结合其余m-1个因子的每一个,依式(8)计算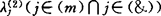 .然后重复使用1.中的①一③步骤,求出
.然后重复使用1.中的①一③步骤,求出
如果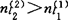 ,则继续吸收第2个因子xl2(否则挑选因子的步骤结束)。此时(&)={l1,l2}
,则继续吸收第2个因子xl2(否则挑选因子的步骤结束)。此时(&)={l1,l2}
(福州大学郭福星教授撰)