The extension of the linear regression model to the case where there is more than one explanatory variable (see regression). For the case of p X-variables and n observations the model is
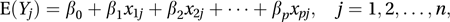 where β0, β1,…, βp are unknown parameters. An equivalent presentation is
where β0, β1,…, βp are unknown parameters. An equivalent presentation is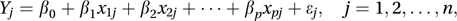 where ε1, ε2,…, εn are random errors.
where ε1, ε2,…, εn are random errors.In practice the explanatory variables may be related as in the quadratic regression model
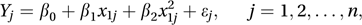 the cubic regression model
the cubic regression model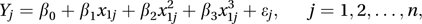 and the general polynomial regression model (also termed a curvilinear regression model)
and the general polynomial regression model (also termed a curvilinear regression model)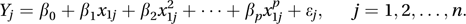
In matrix terms the model is written as
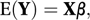 where Y is the n×1 column vector of random variables, β is the (p+1)×1 column vector of unknown parameters, and X is the n×(p+1) design matrix given by
where Y is the n×1 column vector of random variables, β is the (p+1)×1 column vector of unknown parameters, and X is the n×(p+1) design matrix given by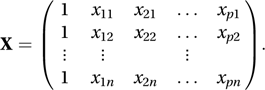 Equivalently,
Equivalently,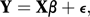 where ɛ is an n×1 vector of random errors.
where ɛ is an n×1 vector of random errors.Usually it is assumed that the random errors, and hence the Y-variables, are independent and have common variance σ2. In this case, the ordinary least squares (see method of least squares) estimates (see estimator) of the β-parameters are obtained by solving the set of simultaneous equations (the normal equations) which, in matrix form, are written as
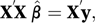 where X′ is the transpose (see matrix) of X and y is the n×1 column vector of observations (y1 y2…yn)′. The matrix X′X is a symmetric matrix. If it has an inverse then the solution is
where X′ is the transpose (see matrix) of X and y is the n×1 column vector of observations (y1 y2…yn)′. The matrix X′X is a symmetric matrix. If it has an inverse then the solution is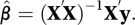
The variance-covariance matrix of the estimators of the β-parameters is σ2(X′X)−1. The Gauss–Markov theorem shows that β is the minimum variance linear unbiased estimate of β̂.
If the random errors are not independent or have unequal variances then ordinary least squares is inappropriate and weighted least squares may be appropriate. If the random errors are influenced by the X-variables, then a possible approach is to identify (if possible) W-variables that are highly correlated with the X-variables, but not with the errors. These W-variables are called instrumental variables. The subsequent analysis, commonly used in econometrics, uses two-stage least squares, in which the first stage involves the regression of the X-variables on the W-variables to obtain fitted values:
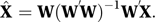
These values are then used in place of the X-values in the regression for Y to give the estimate β̂2:
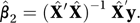
A perennial problem with multiple regression models is deciding which of the X-variables are really needed and which are redundant.
A related problem is that of collinearity (or multicollinearity). Suppose, for example, that the two explanatory variables Xj and Xk approximately satisfy the relation Xj=a+bXk. In this case a multiple regression model that involves both Xj and Xk will run into problems, since either variable would be nearly as effective on its own. The situation can arise with other numbers of X-variables: in all cases the result is that the matrix X′X is nearly singular. The equation X′Xβ̂=X′y is then said to be ill-conditioned. One suggestion is to replace the usual parameter estimate by
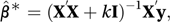 where k is a constant and I is an identity matrix. This technique is called ridge regression. A plot of the elements of β̂* against k is called a ridge trace and can be used to determine the appropriate value for k. The estimates of the β-parameters obtained using this method are biased (see estimator) but have smaller variance than the ordinary least squares estimates.
where k is a constant and I is an identity matrix. This technique is called ridge regression. A plot of the elements of β̂* against k is called a ridge trace and can be used to determine the appropriate value for k. The estimates of the β-parameters obtained using this method are biased (see estimator) but have smaller variance than the ordinary least squares estimates.When there are many X-variables interpretation of the fitted model can be difficult and there may be several variables whose importance is questionable by reason of the small values of the corresponding β-parameters. A procedure that usually results in many of these β-parameters being set to zero (so that the corresponding explanatory variable is removed) is the lasso, in which the usual estimation procedure (see method of least squares) is modified by the restriction that
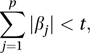
where t is a tuning constant (see M-estimate).
For methods of evaluating the fit of a multiple regression model, see regression diagnostics. See also model selection procedure; stepwise procedure.
See regression analysis.
- automatic data conversion
- linear equation
- linear expansivity
- linear filter
- linear first‐order differential equation
- linear function
- linear grammar
- linear group
- linear independence
- linear interpolation
- linear inverter
- linearization
- linearizing
- linear list
- linear logic
- linear-logistic model
- linearly dependent
- linearly dependent and independent
- linearly graded junction
- linearly independent
- linearly polarized wave
- linear map
- linear model
- linear molecule
- linear momentum