Various statistics that give information about the reliability of the estimates of the multiple regression model
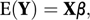
where Y is an n×1 vector of independent and identically distributed response variables, β is a p×1 vector of unknown parameters, and X is an n×p matrix. If β is replaced by its least squares estimate, β̂, the estimated column vector of fitted values, ŷ, is given by
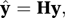
where the n×n matrix H, the hat matrix, is given by
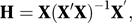
X′ is the transpose of X, (X′X)−1 is the inverse of the matrix X′X, and y is the column vector of observed values. Denote the element in the jth row and kth column of H by hjk. The fitted value, ŷj, for the jth observation, yj, is given by
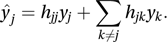 Thus there is a direct link between the fitted and observed values in the form of hjj. This is the leverage: a large value (e.g.>2p/n) indicates an observation having a large influence on the form of the fitted model.
Thus there is a direct link between the fitted and observed values in the form of hjj. This is the leverage: a large value (e.g.>2p/n) indicates an observation having a large influence on the form of the fitted model.The most obvious guide to the fit of a model are the residuals, e1, e2,…, where ej is given by
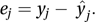
If the random variables have common variance σ2 and if s2 is an unbiased estimate of σ2, then the standardized residual is sometimes defined as ej/s. However, an unbiased estimate of the variance of ej is not s2 but s2(1−hjj) and a more appropriate residual (having unit variance if the model is correct) is given by rj, where
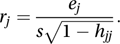 This is sometimes called the standardized residual and sometimes the Studentized residual.
This is sometimes called the standardized residual and sometimes the Studentized residual.The deletion residual is given by
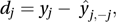
where ŷj,−j is the fitted value for observation j based on the fit of the model to all the observations except the observation yj. Dividing the deletion residual by its estimated standard error, we get the Studentized deletion residual which can be written as
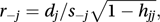 where s2−j is the unbiased estimate of σ2 obtained when observation j is omitted. Confusingly, this may also be called the Studentized residual. See also Anscombe residual; deviance residual.
where s2−j is the unbiased estimate of σ2 obtained when observation j is omitted. Confusingly, this may also be called the Studentized residual. See also Anscombe residual; deviance residual.A related influence statistic is DFFITS, which is an abbreviation for difference in fits. For observation j, DFFITSj is
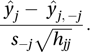 The influence statistic DFBETA (difference in beta values) applies the idea embodied in DFFITS to the parameter estimates rather than the fitted values. For βk, DFBETAk,−j is
The influence statistic DFBETA (difference in beta values) applies the idea embodied in DFFITS to the parameter estimates rather than the fitted values. For βk, DFBETAk,−j is 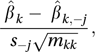 where β̂k is the estimate of βk from the complete data, β̂k,−j is the estimate when observation j is omitted, and mkk is the corresponding diagonal element of the p×p matrix (X′X)−1.
where β̂k is the estimate of βk from the complete data, β̂k,−j is the estimate when observation j is omitted, and mkk is the corresponding diagonal element of the p×p matrix (X′X)−1.A statistic that usefully combines information about leverage and influence is Cook's statistic, Dj, given by
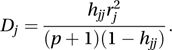 This statistic (introduced by Cook in 1977) can also be interpreted as measuring the effect on the parameter estimates of omitting the jth observation. Large values point to possible outliers.
This statistic (introduced by Cook in 1977) can also be interpreted as measuring the effect on the parameter estimates of omitting the jth observation. Large values point to possible outliers.
- semidecidable set
- semidecision procedure
- semidetached binary
- semidiameter
- semi-direct product
- semi-empirical calculations
- semi-forbidden line
- semigroup
- semi-infinite
- semi-interquartile range
- semilunar valve
- semimajor axis
- semi-Markov process
- semimetal
- semi-metric
- seminal receptacle
- seminal vesicle
- seminiferous tubules
- Seminole Wars (1816–18)
- semi-norm
- semiochemical
- semiology
- semiotics
- semi-parametric model
- semi-permeable membrane